智能系统设计-罐装知识
ANN
ANN停止的标准
- 特定次数的迭代(iteration)之后
- 输出的误差低于阈值(threshold)
- 独立验证集(separate validation set)上的错误小于某些标准(criteria)。
ANN各项参数的影响
学习率:过小,迭代(iteration)过多;过大,可能错过最优解,在损失函数(lossfunction)最低点震荡(oscillate)
动量(momentum):过小,陷入局部最优解(local minima);过大,造成下降方向与梯度方向差异较大,产生震荡。
*附:动量的作用: 1.使得训练时穿过(rolling through)局部最优(local minima)*
2.加大梯度不变时的步长(step size),提升收敛速率
迭代次数(learning iterations):过小,欠拟合,无法捕捉数据集的通用特征(characteristic)。过多,浪费计算资源,导致过拟合(overfitting)。
*附:防止过拟合的方法:1. 使用验证数据集(validation data set),当误差增加时,则立即停止训练*
2.使用预定义的迭代次数停止训练
3.使用预定义的误差阈值(threshold)停止训练
数据集:越大越好,大的good for training
超参数(hyperparameter):手动(manually)设置的参数,用于优化训练算法。
神经网络类型的数种概念
深度学习:使用多层非线性处理单元的级联进行特征提取和转换(feature extraction and transformation)。每一层都使用前一层的输出作为输入。隐藏层的作用:可以为模型引入其他影响因子(introducing extra factors),为网络提供了对数据中的非线性进行建模的能力。
迁移学习:使用其他数据进行预训练(pretrained)后的模型进行再次训练,以处理新数据。可以有效节省数据集(节省监督学习的数据标注量)。
单层感知机网络的局限性:单层感知机只能分类线性边界,因此XOR这样的需要多条线进行分割(requires more than one line to it),无法使用单层感知机进行建模。
循环神经网络(Recurrent Neutral Network):一种常用于处理时间序列数据的深度学习网络。隐藏层包含自反馈,序列的当前输出也与前一个输出相关,因此有内部记忆(internal memory)。擅长:处理未分割的手写识别或语音识别等(unsegmented connected handwriting recognition or speech recognition)缺点:1. 大多数RNN都存在缩放问题(scaling issue)。2. 在有大量输入数据集时,RNN不易训练。
*附:使用feedforward网络处理时间序列数据:需要将时间序列作为输入,例如以x(t), x(t-1), x(t-2)作为输入。训练同最正常神经网络*
卷积神经网络(Convolutional neural networks):常用于图像识别的神经网络。由多层卷积层-池化层还有一个全连接层(full connected layer)构成。卷积层:提取输入数据的特征。池化层:提取卷积结果的显著特征,减少计算量。被用于:手写识别、图像分类、人脸识别(face recognition)
训练方式
监督学习(supervised):需要使用被标注的数据(labeled data)进行学习。监督学习算法分析训练数据并产生一个推断函数,该函数可用于映射新样本。前馈神经网络就是一种有监督学习系统。
无监督学习(unsupervised):无需使用被标注的数据,在无标签数据中寻找隐藏结构(hidden structure),只是将现有的数据进行聚类(clustering)和分类(classifying)。SOM就是典型的无监督学习。
常用训练算法-梯度下降(Gradient descent):计算损失函数在当前点的梯度,并沿着梯度的相反(opposite)方向更新参数,直到找到损失函数的最小值,即朝着上升率最快的反方向行走。
验证数据集的意义(validation set):验证集是用于在训练时测试网络的数据,通常用于防止过拟合(overfitting)。
Fuzzy System
推理模型差异
Mamdani:使用连续的输出模糊集,可以能够以更直观、更人性化的方式描述专业知识。但需要更大的计算负担。
Sugeno:输出模糊集使用离散的特定数字。在计算上效率很高,并且可以很好地嵌入优化和自适应技术,这使得它在控制问题中非常有吸引力,特别是对于动态非线性系统。
归一化模糊变量的优点
- 更有效地利用论域(universe of discourse)的间隔
- 将规则库推广到更大范围的模糊化(To generalize the rule base for a wide range of fuzzification)
- 为调教(tuning)提供了更多灵活性(flexibility)
Genetic Algorithm
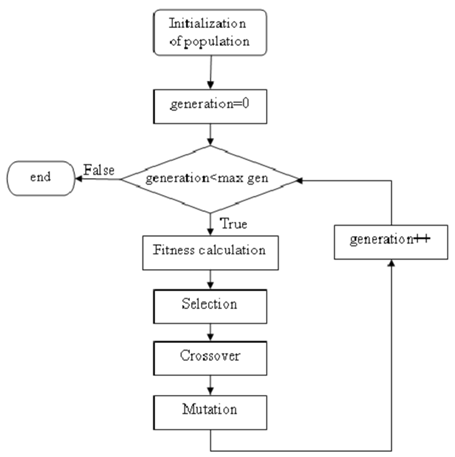
GA的一个世代的步骤及其意义
编码(Encoding):将问题的可能解决方案视为种群中的个体(individuals)。如果解决方案可以分为一系列小步骤(构建块 Building blocks),那么这些步骤由基因表示,而一系列基因(染色体 chromosome)将编码整个解决方案。这样,问题的不同解决方案在遗传算法中表示为个体的染色体。
适应度函数(fitness function):代表一个问题的期望解的主要要求(即最便宜的价格,最短的路线,最紧凑的安排等)。该函数计算并返回单个解决方案的适应度。
选择算子(Selection operator):定义当前种群中个体被选择繁殖的方式。有许多策略(例如轮盘赌,排名,锦标赛选择等),,选择最适合当前算法的。
交叉(Crossover):定义了父母的染色体如何混合,以获得其后代的遗传密码(例如,一点,两点,均匀交叉等)。这个运算符实现了继承属性(inheritance property)(子代继承(inherit )父代的基因)。
变异(Mutation):算子会对后代的遗传密码(genetic codes)产生随机变化。这种操作符需要为遗传密码带来一些随机多样性(random diversity)。在某些情况下,如果不使用变异算子,遗传算法就无法找到全局最优解。
下面给出算法的流程图:
表型和基因型的差异
表型(phenotypes):表型是基因型通过解码和表达所产生的实际特征或行为(actual characteristic or behaviour)。在遗传算法中,表型通常是基因型经过解码后得到的解。
基因型(genotypes):基因型是个体的遗传信息(individual’s genetic information)的编码表示。在遗传算法中,基因型通常表示为一个字符串或数组,其中每个元素代表一个基因,表型经过编码(encoding)即可得到基因型。
GA训练停止条件:
- 超出允许的CPU时间(CPU time)后停止
- 适应度超过给定阈值
- 在一段时间内,改善不明显
- 种群多样性(population diversity)在阈值以下
GA参数的影响
种群大小过大:可以找到解决方案,但是计算量提高
交叉率过大:可能产生震荡,不收敛
变异率过小:激励不足(not enough excitation),可能陷入局部最优解
GA是全局优化算法的原因
GA是一种随机算法( stochastic algorithm),它从分布在整个解空间(solution space)范围内的随机数开始,从而在整个解空间范围内寻找可行解,使算法成为一种全局优化搜索引擎。
图像处理
图像压缩的流程
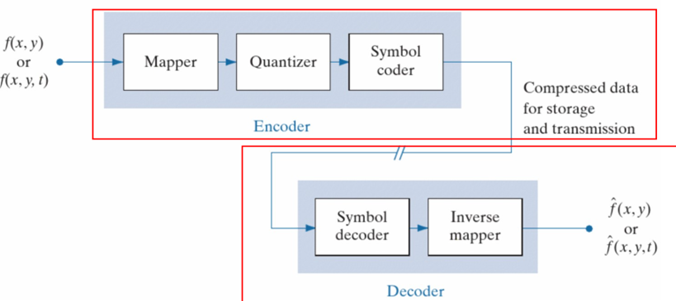
mapper:将数据变换(transform)到对压缩有友好的域上。其中一些mapper与傅里叶有关,例如DCT。
Quantization:引入误差的主要步骤。That introduces something that helps the compression, but limits us from being able to reconstruct exactly the image.
Symbol encoder:将图像使用更高效的编码(例如可变长的霍夫曼编码)进行存储。
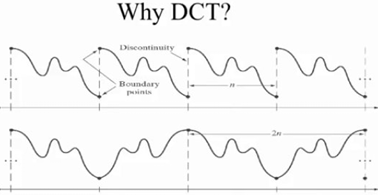
JPEG使用DCT的原因
相较于DFT,DCT的边界拓展更加连续
直方图均衡化的已知条件
图像复原的步骤
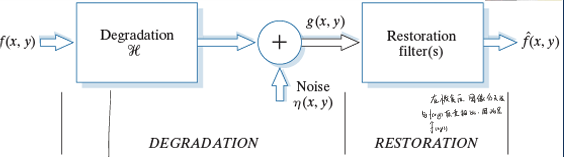
逆滤波
在拍摄图像时,由于相机系统、运动干扰等引入噪声$h(x,y)$
那么在频域上,通过除$H(u,v)$即可
逆滤波的难点是如何估计退化函数H,通常情况是根据经验预测图像所经受的退化类型。
维纳滤波
基本思想:将原图和复原图的均方差表达式最小化
如果将上述期望式子展开,用DCT变化到频率,则有
由于$\frac{p_\eta}{p_f}$通常是个常数,因此记为$K$。通过尝试不同的K值后,对上式进行IDFT观察图像复原的情况,从而复原图像。